Human gameplay is a visually grounded interaction loop in which players act, reflect on failures, and watch tutorials to refine strategies. Can Vision-Language Models (VLMs) also learn from video-based reflection? We present GameVerse, a comprehensive video game benchmark that enables a reflective visual interaction loop. Moving beyond traditional fire-and-forget evaluations, it uses a novel reflect-and-retry paradigm to assess how VLMs internalize visual experience and improve policies. To facilitate systematic and scalable evaluation, we also introduce a cognitive hierarchical taxonomy spanning 15 globally popular games, dual action space for both semantic and GUI control, and milestone evaluation using advanced VLMs to quantify progress. Our experiments show that VLMs succeed in simple tasks, but struggle to generalize in complex games. Meanwhile, they benefit from video-based reflection in varied settings, and perform best by combining failure trajectories and expert tutorials—a training-free analogue to reinforcement learning (RL) plus supervised fine-tuning (SFT).
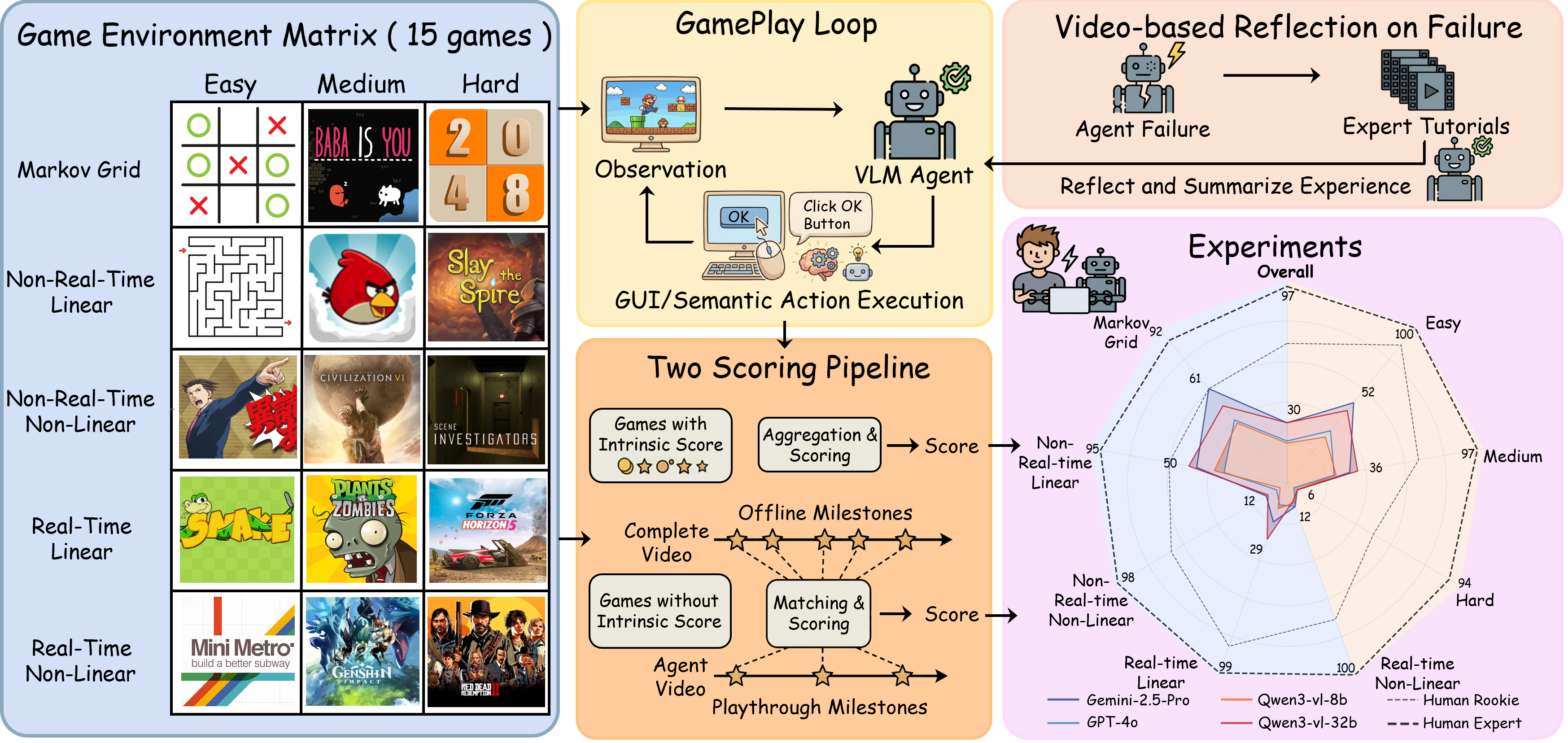
Figure 1. Overview of GameVerse, which effectively probes the capability boundaries of VLMs in video game worlds. GameVerse supports dual action space, enables human-like reflection by integrating failure and tutorial videos, and delivers process score.
We construct a cognitive hierarchical taxonomy based on three cognitive axes: Image Structure (Grid/2D/3D), Temporal Dynamics (Real-time/Non-Real-time) and Causal Linearity (Linear/Non-linear), resulting in five distinct categories. GameVerse selects 15 globally popular video games distributed across these categories, with easy, medium, and hard difficulty tiers per category.
To assess both high-level reasoning and low-level control, we define two action modes: Semantic Actions: High-level semantic actions (e.g., "Position(1,3)"), testing the agent's perception and reasoning. GUI Actions: Low-level GUI operations (e.g., KeyPress(A)), testing end-to-end precise visual control.
The paradigm consists of four steps: (1) Trial and Failure. The agent first attempts the game task. If it fails, the system records the sequence of visual observations leading to the negative outcome. (2) Expert Demonstration Retrieval. The system retrieves an expert walkthrough from online gameplay videos. (3) Visual Reflection. The VLM acts as a reflector. It takes both its failure trajectory and the expert demonstration as visual input. The model is prompted to contrast the two, analyzing the divergence in strategy and execution, and generating condensed empirical reflections. (4) Policy Update. These reflections are injected into the agent's system prompt, enabling it to re-attempt the task with the new context.
We introduce a milestone scoring pipeline that leverages advanced VLMs to quantify agent progress purely from pixels. Phase 1: Offline Milestone Detection. We employ an advanced VLM to watch expert walkthrough videos and extract structured milestone references. Phase 2: Online Scoring. Following gameplay, an advanced VLM analyzes the playthrough video, comparing the agent's trajectory against the reference milestones to calculate a process-oriented score. This method scales easily to closed-source commercial games where internal state information is inaccessible.
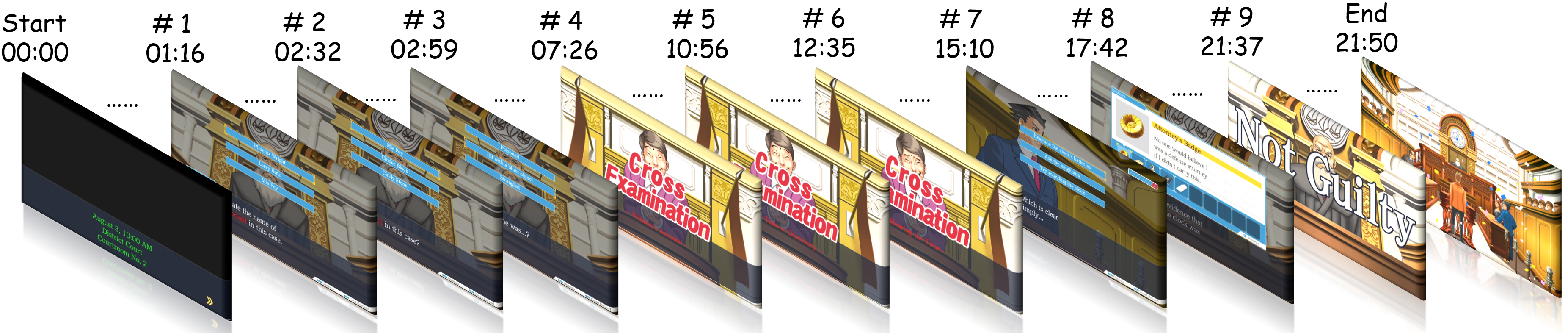
9 milestones are extracted by Gemini-3-pro in th walkthrough video of Ace Attorney.
We demonstrate VLM's performance in GameVerse across 15 globally popular video games. Each video shows gameplay trajectories captured in real-time. Videos are arranged in 5 rows (Cognitive Tiers) and 3 columns (Difficulty Tiers). The video has been accelerated.
Comparing 2 VLM models and 1 human player across 5 games: Baba Is You, Angry Birds, Scene Investigators, Plants vs. Zombies, Red Dead Redemption 2.
Comparison of gameplay before and after Video-based Reflection (VR) implementation. The video-based reflection paradigm enables agents to refine gameplay by observing failures and expert tutorials. The improvement demonstrates how VLMs can learn from visual experience and improve policies through the reflect-and-retry paradigm. Representative comparison games: Tic-Tac-Toe, Angry Birds, Plants vs. Zombies.
Strategy Evolution: Qwen3-VL-32B transitioned from a purely offensive playstyle to a threat-aware defensive strategy. When facing a column-1 threat (X at A1 + C1), it shifted from placing an aggressive C3 to strategically blocking with B1, successfully forcing a draw against a Minimax AI opponent.
Analysis: By internalizing the concepts of "blocking potential lines" and "countering open threats," Qwen3-VL-32B successfully identified the opponent's vertical winning condition. This shift prioritized structural defense over expansion, effectively neutralizing a high-risk threat into a stable draw.
Strategy Evolution: GPT-4o-mini transitioned from inefficient direct fire to a sophisticated parabolic trajectory strategy. Instead of repeatedly striking the frontal obstacle, it now aims for the wooden support structure behind the mound, leveraging gravity to trigger a structural collapse.
Analysis: By internalizing the concept of "arcing over obstacles," GPT-4o-mini successfully bypassed terrain constraints and identified the structural vulnerability, significantly improving overall task efficiency.
Strategy Evolution: GPT-4o-mini transitioned from repeatedly dragging plants to invalid positions to correctly identifying plantable tiles. Before reflection, the model kept attempting to place a second Peashooter on non-plantable spots, wasting all available steps without ever starting the actual battle. After reflection, it successfully placed the plant on a valid tile, allowing the game to proceed normally.
Analysis: By internalizing the concept of "strategic tile selection," GPT-4o-mini shifted its attention from blindly dragging plants to consciously identifying valid, unoccupied tiles on the lawn, resolving the repeated placement failure and enabling successful game progression.
We evaluate the performance of 7 VLMs (Qwen3-VL-8B/32B, GPT-4o/4o-mini, Gemini-2.5-Pro/Flash, Seed-1.8) across 15 GameVerse games, comparing them against Random, Human Rookie, and Human Expert baselines.
| Model | VR | Markov Grid | Non-RT Linear | Non-RT Non-Linear | Real-time Linear | Real-time Non-Linear | Avg. Rank | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TicTacToe | Baba | 2048 | Maze | AngryBird | Slay | Attorney | Civilization | Scene | Snake | PvZ | Horizon | Metro | Genshin | RDR2 | |||
| Three Baselines | |||||||||||||||||
| Random | — | 26.3 | 10.8 | 1.2 | 21.3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 7.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 16.5 |
| Human Expert | — | 98.9 | 100 | 77.1 | 100 | 85.3 | 99.4 | 100 | 100 | 94.2 | 100 | 100 | 98.1 | 100 | 100 | 100 | 1.6 |
| Human Rookie | No | 85.1 | 83.4 | 15.9 | 99.3 | 46.4 | 34.2 | 77.4 | 54.1 | 70.4 | 93.2 | 89.3 | 73.9 | 91.2 | 63.3 | 58.4 | 4.1 |
| Yes | 99.4 | 100 | 47.3 | 100 | 74.2 | 81.3 | 100 | 96.4 | 90.1 | 100 | 97.9 | 85.3 | 98.4 | 88.2 | 83.1 | 2.2 | |
| Seven Vision-Language Models | |||||||||||||||||
| Qwen3-VL-8B | No | 53.3 | 60.0 | 4.4 | 80.3 | 19.6 | 11.7 | 7.1 | 0.0 | 6.3 | 2.2 | 33.4 | 3.2 | 7.8 | 14.3 | 7.2 | 12.4 |
| Yes | 51.8 | 70.4 | 5.1 | 89.4 | 31.2 | 7.4 | 26.1 | 0.0 | 6.3 | 0.0 | 51.3 | 3.2 | 8.3 | 14.3 | 7.2 | 11.6 | |
| Qwen3-VL-32B | No | 70.6 | 73.3 | 6.4 | 100 | 41.6 | 8.2 | 17.3 | 8.3 | 8.3 | 42.6 | 41.2 | 3.2 | 5.4 | 14.3 | 7.2 | 9.5 |
| Yes | 63.1 | 80.0 | 6.1 | 100 | 59.4 | 11.3 | 37.2 | 8.3 | 8.3 | 33.4 | 48.3 | 3.2 | 11.2 | 14.3 | 10.0 | 7.8 | |
| GPT-4o-mini | No | 34.4 | 60.0 | 1.3 | 77.1 | 16.7 | 2.0 | 0.0 | 0.0 | 3.2 | 0.0 | 27.6 | 3.2 | 4.2 | 14.3 | 10.0 | 14.1 |
| Yes | 43.2 | 68.3 | 1.4 | 91.3 | 13.3 | 2.0 | 0.0 | 0.0 | 3.2 | 0.0 | 22.4 | 3.2 | 7.1 | 14.3 | 10.0 | 13.6 | |
| GPT-4o | No | 58.6 | 60.9 | 3.8 | 80.2 | 14.3 | 2.0 | 18.2 | 0.0 | 0.0 | 0.0 | 32.2 | 2.4 | 11.2 | 14.3 | 10.0 | 13.3 |
| Yes | 64.2 | 60.0 | 3.4 | 85.1 | 15.4 | 2.0 | 33.3 | 0.0 | 0.0 | 0.0 | 36.4 | 3.2 | 14.3 | 14.3 | 10.0 | 12.3 | |
| Seed-1.8 | No | 92.3 | 80.0 | 9.1 | 87.8 | 29.4 | 39.6 | 33.3 | 22.2 | 3.2 | 7.2 | 26.1 | 5.4 | 1.3 | 14.3 | 10.0 | 9.3 |
| Yes | 100 | 80.0 | 18.2 | 100 | 57.2 | 28.4 | 59.3 | 19.5 | 8.3 | 10.4 | 22.1 | 2.4 | 1.4 | 14.3 | 7.2 | 8.4 | |
| Gemini-2.5-Flash | No | 88.2 | 80.0 | 7.8 | 100 | 9.4 | 2.0 | 33.3 | 0.0 | 3.2 | 20.4 | 51.1 | 5.4 | 14.6 | 14.3 | 10.0 | 9.3 |
| Yes | 95.1 | 80.0 | 11.4 | 100 | 10.2 | 2.0 | 29.3 | 0.0 | 8.3 | 10.4 | 55.3 | 5.4 | 19.1 | 14.3 | 13.4 | 8.1 | |
| Gemini-2.5-Pro | No | 90.0 | 80.0 | 13.2 | 100 | 32.7 | 4.4 | 37.2 | 0.0 | 0.0 | 24.2 | 33.4 | 3.2 | 11.3 | 14.3 | 10.0 | 9.2 |
| Yes | 100 | 80.0 | 26.4 | 100 | 42.2 | 7.9 | 48.3 | 0.0 | 0.0 | 68.4 | 30.3 | 5.4 | 18.2 | 14.3 | 10.0 | 7.5 | |
Performance Hierarchy: Gemini-2.5-Pro achieves the highest average ranking (7.5/9.2) among all VLMs, followed by Gemini-2.5-Flash (8.1/9.3), Gemini-2.5-Pro (8.4/9.3), and Qwen3-VL-32B (7.8/9.5).
The Rich-Get-Richer Effect: Reflection generally yields improvements, but its efficacy is non-uniform. Gains scale positively with model capability (Gemini-2.5-Pro improves 6.47% vs. GPT-4o-mini with 1.60%) and negatively with cognitive complexity (dropping from 4.4% in Non-Real-time to 1.7% in Real-time).
The Generalization Gap: Human players demonstrate remarkable generalization across all game types, while VLM agents exhibit severe degradation as complexity increases. In Easy games like Tic-Tac-Toe, Gemini-2.5-Pro achieves perfect scores (100), matching human expert baselines (98.9). In Hard games like Scene or RDR 2, model performance collapses to 0, falling short of human rookie (58.4~70.4).
The Knowing-Doing Gap: Model averages 50.5 in semantic mode, consistently outperforming the GUI mode average of 33.5. While current VLMs possess strong reasoning capabilities for high-level planning, they still struggle with the visual grounding required to translate these plans into precise pixel coordinates.
Video-Based Reflection Benefits: VLMs benefit from video-based reflection in varied settings, and perform best by combining failure trajectories and expert tutorials—a training-free analogue to reinforcement learning (RL) plus supervised fine-tuning (SFT).
@article{gameverse2026,
title={GameVerse: Can Vision-Language Models Learn from Video-based Reflection?},
author={Zhang, Kuan and Liu, Dongchen and Zhao, Qiyue and Hou, Jinkun and Zhang, Xinran and Xie, Qinlei and Liu, Miao and Li, Yiming},
journal={arXiv},
year={2026},
url={https://arxiv.org/abs/2603.06656}
}Background picture in hero section generated by Nano Banana